前言
借助mach-o view源码对Mach-O的知识做一次系统的记录。但是这个开源库已经近5年没有更新了,不仅下下来各种无法编译,并且很多mach-o信息也无法解析,于是我对它进行一些修改,可以直接拿我fork过来的工程 ,已经修复了一些问题并兼容了苹果最新的mach-o结构。
结构分析
首先大致描述下Mach-O文件的结构:
graph LR A[header] --> B[LoadCommands] B --> C[TEXT] C --> D[DATA] D --> E[LINKEDIT]
关于mach-o的介绍网上很多,这里只针对一些比较重要的点分析:
LINK EDIT
之前一直弄不懂这个segment是干吗的。实践发现无论是那种Mach-O文件都有__LINKEDIT segment,表示的是 sections DATA段之后的部分,包括符号表,字符串表,动态链接器信息和函数签名等等。也就是说这一段信息其实描述的是链接相关的信息,供Link Editor在链接时使用的。
1 | //找到__LINKEDIT的基地址 |
网上有些人包括我第一眼看到这个linkedit_base都出现一个错误,认为这玩意就是__TEXT段的vmaddr。而且我试验那个Mach-O还恰好就是这样,所以好奇为啥原作者要这么麻烦。。。
后来经过实践发现犯了如下错误:
有些mach-O中segment的vm size并不等于file size。所以这里并不是等于__TEXT段的虚拟地址。只有linkedit_segment->vmaddr - linkedit_segment->vmoffset才等于__TEXT段的虚拟地址。
vm size描述是虚拟空间大小,通常等于大于或等于文件真正的大小。而file size描述是文件映射过来的段空间大小,也就是file size才是真正的文件映射到内存段的数据大小。
我们知道为了程序内存管理通常采用一整块的逻辑地址空间(虚拟空间)来加载程序,虚拟内存空间是以页为单位的,大小为4KB(4096),所以虚拟地址一定是4096的倍数。而实际大小File size并不是,这就是vm size大于等于file size的原因。由于符号表,字符串表和indirect symbol table存放在LINK EDIT段,由它的vmaddr - fileoff才能寻找到真正的文件起始位置对应的逻辑地址。
符号表
LC_SYMTAB指导链接器如何加载符号表信息,结构如下:
1 | struct symtab_command { |
但是还有个LC_DYSYMTAB是什么呢,这个其实是方便link editer的,它对符号进行了详细的划分,把符号表共分为三块:local symbols仅仅用于debug。defined symbols内部定义的符号,undefined symbols外部共享库定义的符号(内部未定义的)。然后还保存了一些动态链接库辅助信息,结构如下:
1 | struct dysymtab_command { |
通过symbol table我们就可以获取到每个符号的信息,结构如下:
1 | struct nlist_64 { |
通过以上信息我们可以知道符号是如何在Mach-O中保存的。那么怎么找到符号呢?
查找符号
动态链接器可以在加载时或者是运行时绑定程序,具体取决于编译时的选项:
just in time binding(lazy binding)表示动态链接器将会在初次使用符号引用时进行绑定。动态链接器加载动态库依赖于程序加载的时机,并且动态库的符号直到被使用时才被绑定。
load time binding表示动态链接器在加载时即绑定所有的符号,使用ld的bind_at_load选项可以在加载时时绑定所有的外部符号。如果不设置该选项默认为just in time binding(lazy binding)`。
在预绑定时,符号会被预绑定到一个默认的地址,静态链接器会给每一个undefined external symbol设置默认地址来使用,如上一节中了解的默认情况下nslist的外部符号会有一个默认的地址。在运行时,动态链接器只会验证这些默认地址没有因为编译或者重计算而改变,如果发生了改变则动态链接器会清除掉undefined external symbol预绑定的地址,然后变成just in time binding方式进行符号的绑定。
预绑定需要每一个framework指明它需要的虚拟内存地址空间,所有预绑定的地址不会发生重复。通过设置LD的prebind选项可以开启预绑定。弱引用的符号动态链接器如果找不到相应的定义则会设置为NULL然后继续加载程序,程序可以运行检查一个引用是否为NULL,如果是则不会处理。
符号又分为两种:non lazy symbols指的是不能延迟加载的符号,必须在编译时就确定好内存地址,这些符号往往时是动态链接依赖的符号。而lazy symbols指的是可以延迟加载的符号。前者存在于__DATA_CONST segment的__got section,后者存在于__DATA segment下的__la_symbos_ptr setction。通过它们可以获取到程序中所有引用到的符号,因此如果想通过这里查找符号并进行处理一定得是先使用这个符号,保证在mach-o中存在。
Non Lazy Symbols
首先分析下non lazy symbols。可以看到其实是一个就是一个指针数组,指向的是函数指针或者变量的地址,可以看到由于它们都不在当前image内,所以都还是空指针:

那么它是如何映射到符号的,通过的也是indirect symbol table,LoadCommand中标识了它在indirect symbol table中的偏移,
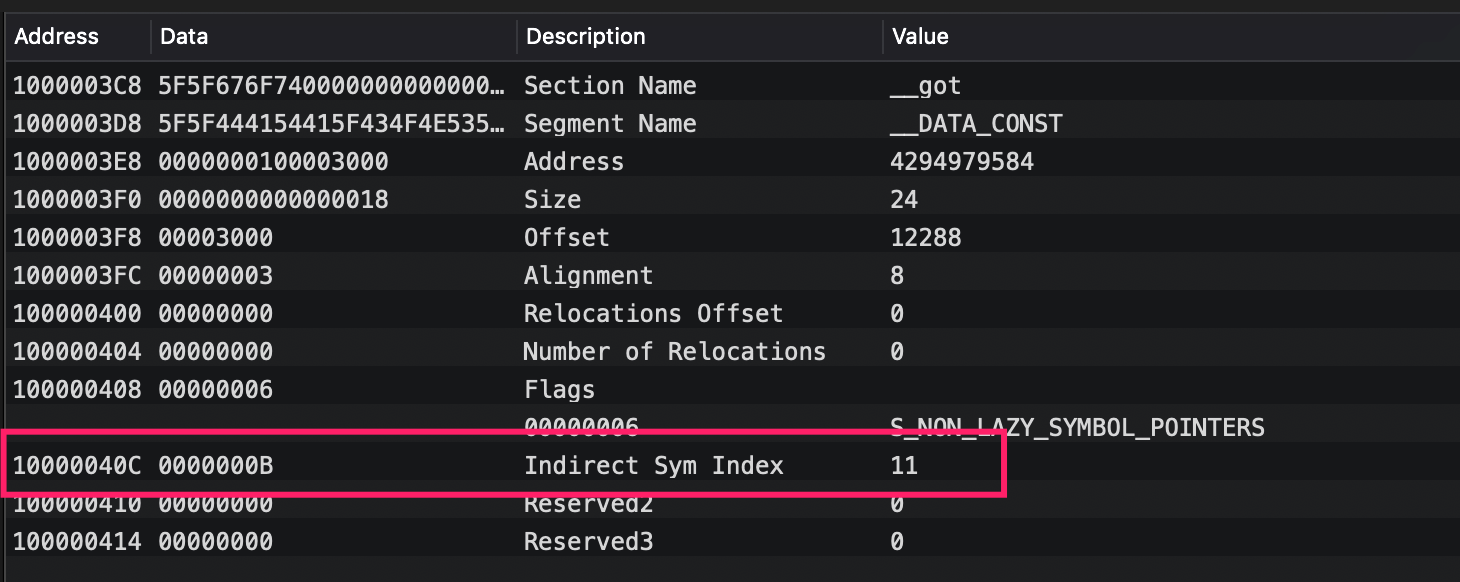
通过indirect symbol table对应位置开始遍历即可找到对应的符号信息,找到指针对应的符号在符号表中的index为 0x95 = 149:
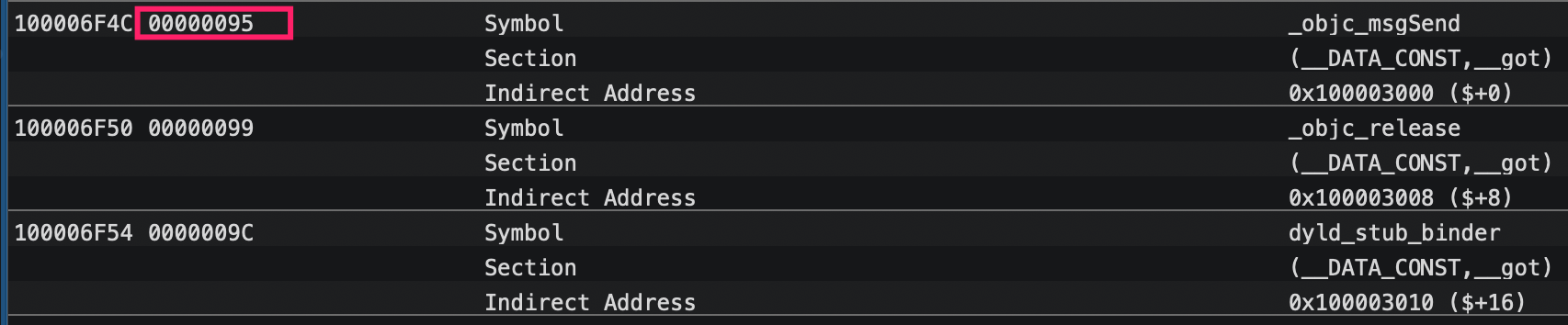
在符号表中找到符号,它是一段nlist结构的字节:
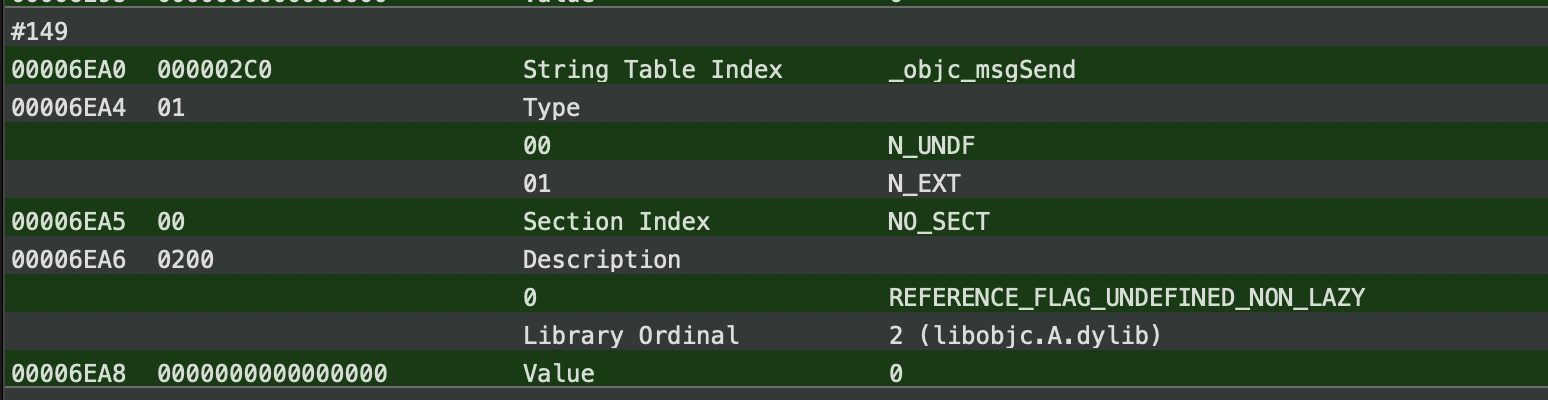
注意indirect symbol table和指针数组是对应的顺序,但是符号表并不是,因此必须indirect symbol table来进行符号的查找。
Lazy Symbols
lazy symbols标识可以延迟绑定的符号,通常是其它共享库中的符号,当第一次使用时才通过dyld进行动态绑定,可以看到它的data并不是空的,而是映射到了对应的stub help section。
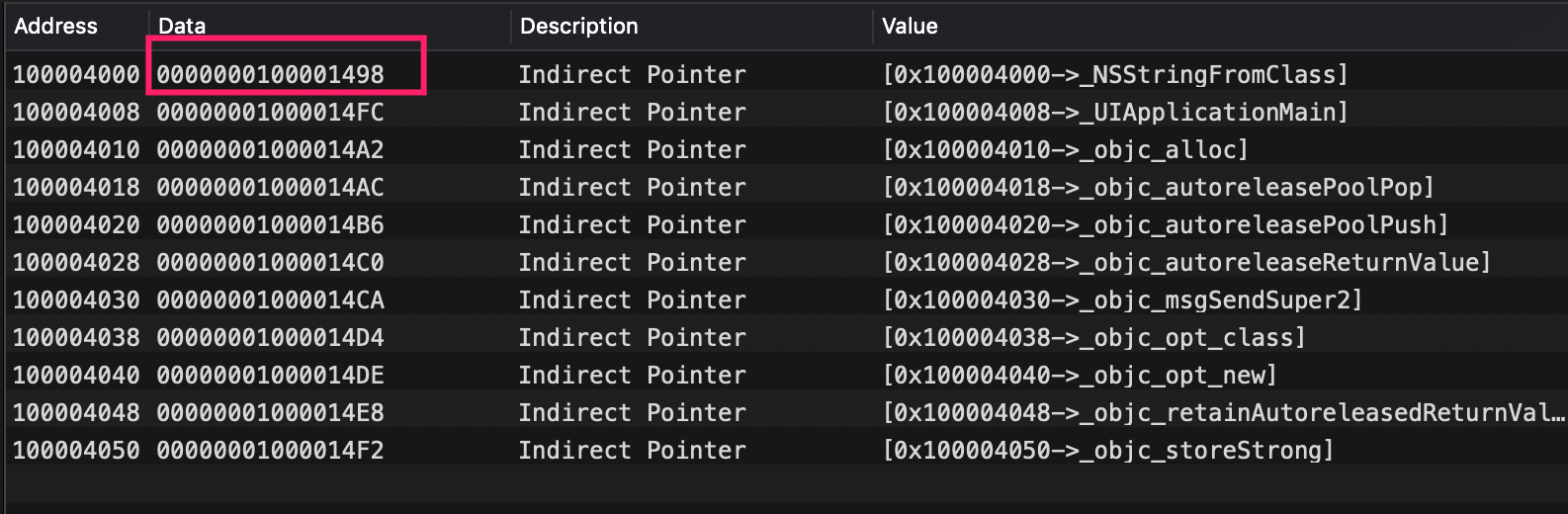
也就是访问延迟加载的指针时触发的stuber helper的函数:
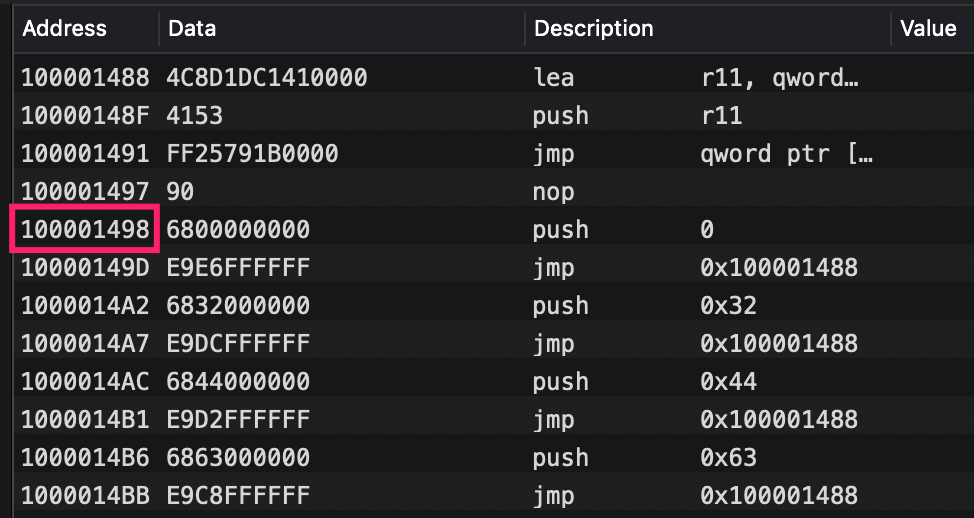
其实是通过dyld进行动态地址绑定,关于这里的详细在下一篇深入理解dyld中会进行详细分析。
当然延迟加载的函数指针和indirect symbol table也是一一对应的,同样可以和上面一样找到对应的符号信息。
Fishhook的工作原理
Fishhook是一个可以通过替换符号函数指针实现函数替换的开源库,本质上通过Mach-O找到符号,然后把函数指针替换为想要替换的函数指针。这里我们分析下fishhook的核心部分:
1.寻找符号表,indirect symbols表:
寻找符号表
1 | static void rebind_symbols_for_image(struct rcd_rebindings_entry *rebindings, |
2.进行函数替换,与源函数指针的保存:
替换函数指针
1 | static void rcd_perform_rebinding_with_section(struct rcd_rebindings_entry *rebindings, |
高效使用FishHook
可以看到FishHook的替换是一个暴力查找的过程,加载的image越多,符号越多耗时越多,通常符号只会存在于一个image中,因此指定image可以一定的减少耗时,好在fishhook提供了指定mach-o header的接口,只是仍然需要我们手动去进行查找,例如替换NSLog,知道是在libSystem.b.dylib则可以直接指定:
1 | uint32_t count = _dyld_image_count(); |
查看运行结果如下:
1 | 2020-02-02 00:54:49.630144+0800 LearnHook[78136:2951341] image count: 339 |
虽然单位是毫秒,由于我这个demo是一个空程序,如果是一个更复杂的程序,替换的符号更多,指定image还是很有必要的。
注意dyld提供的遍历image方法并不是线程安全的,可以用dladdr替换,在FishHook也出现了这个函数,但是只是用于检测image是否存在。。。 正常使用时大概不会出现线程问题8。。。
OC相关数据
对于包含OC代码的mach-o文件,则会单独存在一些oc相关的section,为了方便就直接以demo截图为例:
可见clang分析出了OC数据并和其它信息分开放置了,根据section name可以很容易看出都是什么信息。由于我现在使用的libobjc.framework已经是runtime2.0所以mach-o和1.0已经发生了很多变化,最显著的就是新增了image_info段,以及去掉了__OBJC段,而是把信息挪到了__objc_data段,__objc_const存放的是一些只读的信息,例如类的原始数据等等。
通过runtime源码和dyld源码可以发现,dyld负责加载mach-o文件,然后每加载一个image就通知到runtime解析其中的OC相关数据然后放入runtime哈希表中,包括类表,protocol表等等。
类与分类
在之前的文章中我们探究过类与分类的区别与编译时的小问题,出发的点是查看符号表信息,这一次主要看一下在mach-o的表现以及如何使用。同样看到mach-o符号表中只有源类的符号_OBJC_CLASS_$_TestClass1,因为说白了我们在代码中使用的还是类名来做事情,分类只是OC的一个特殊概念而已,只是runtime在解析后把分类中的数据插入到源类,所以本质上只有源类存在,因此缺少分类参与编译在编译过程并不会产生任何问题,唯一就是运行时缺少了分类里的一些数据。分类在编译时由编译器解析,根据符号找到对应的类之后就变成了类原始数据中的categorys这个指针数组的一员了。因此分类的加载一定依赖类的加载,类的+load一定被优先调用。
每一个类在符号表中都有一个符号存在,它的value指向的就是类数据的指针,而类的数据信息都存在_objc_data这个section,通过classlist中的指针和符号表中OC类的符号的value都指向的是这里。类的结构如下,通过符号address可以找到这样一个数据,就可以知道符号的类结构。
在OC世界里对象都是objc_object结构体指针,共同特点是都有isa,id也不过是一个typedef的别名而已,因此是万能指针。
1 | /// A pointer to an instance of a class. |
类也是objc_object的子结构体:
1 | struct objc_class : objc_object |
data指针指向``__objc_const``这个段的数据,结构如下如class_ro_t`保存着编译时获取的类的原始数据,是不允许运行时修改的:
1 | struct class64_ro_t |
不过OC作为一门动态语言必须得支持动态修改类信息,因此运行时系统在加载的过程又创建了一个可变的class_rw_t,结构如下。它在realizeClass时会把ro的数据拷贝进来,并且会在此时把所有category中数据加载进来,因此类就具有了分类的能力。
1 | struct class_rw_t { |
由此可知类的结构在编译时已经确定,只有ro中有ivar layout和instancesize决定一个类的大小,而它又是只读的,所以运行时无法修改一个确定的类结构,所以category中无法添加成员变量,虽然可以添加属性,但是请注意属性只是一种快捷创建成员变量及其get,set方法的方式。但是由于category在运行时并不能吧ivar拷贝到类中,所以属性也就成了一个空架子,所以当你在分类中添加属性时,属性虽然存在,但是与之匹配的成员变量即get set方法并不产生,因此还是没有意义的,而且可以观察符号表,与之相关符号一个都没有,也就是说一个空的属性。
分类就是一个可以挂载在任何类上的class_rw_t的子集。如果在分类中添加成员变量,Clang直接会报错,所以如果有一天能在分类中添加成员变量,只能在编译时就做到分类的合并才行,但是如果这么做了分类和类还有什么区别呢,尤其是分类真正牛在可以对未知源码的类进行扩展,这在编译时是根本无法做到的。
类的构成可视化如下,可以看到所有方法和属性变量在编译时已经处理好了:

方法调用时从method list中找到找到method,然后找到imp。imp指向的只是__TEXT段的汇编指令。但是可以发现的类方法并没有存在于methodlist,那么类方法怎么调用呢?需要通过元类metaclass。
metaclass与isa
isa是OC的一个概念,实例的isa描述的是实例到底是什么类,表现为_OBJC_class_$_。类的isa描述的是类的元类metaclass,通常类在编译时就确定了isa,在mach-o中表现为指向另一个类一样长的数据段,被编译器以_OBJC_metaclass_$_符号标注的东东,经过分析mach-O中它是一个和类一模一样结构的数据,有自己类似class_t一样的结构以及自己的class_ro_t结构data。
那一张经典的isa指向图这里就不上了,通过数据也可以看出元类的isa指向的是父类的元类,而元类的父类指向的也是父类的元类,此时我们从数据上详细分析metaclass到底是什么:
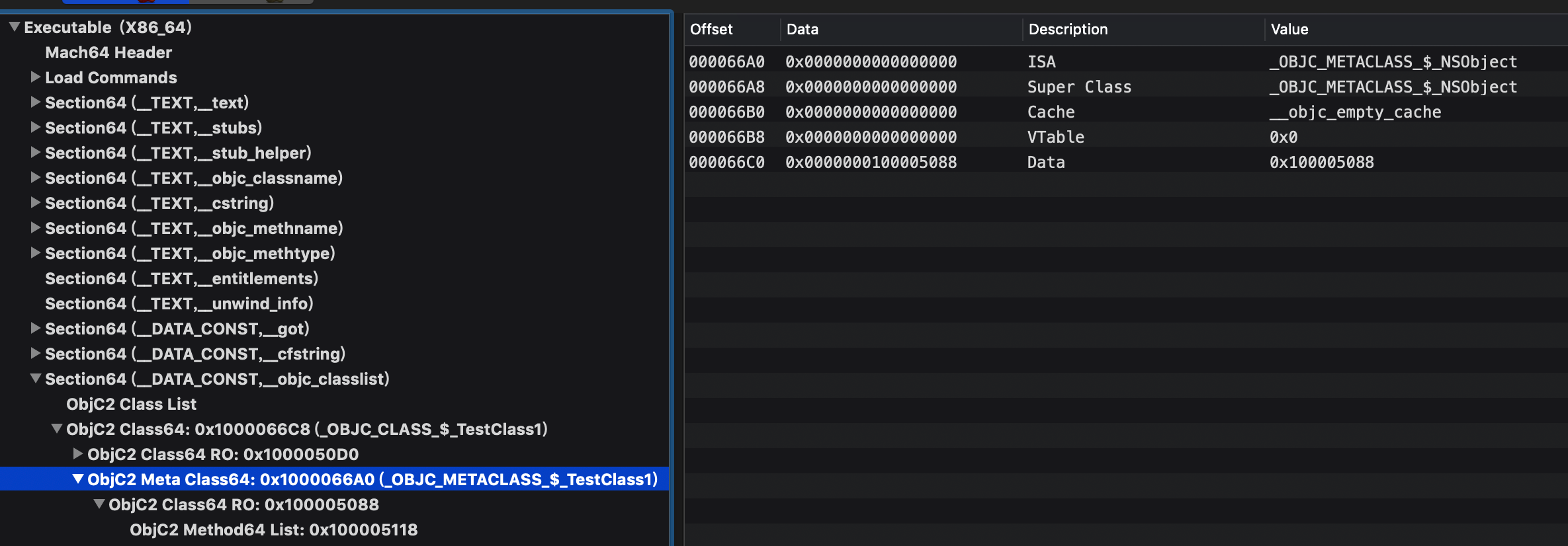
元类有自己的数据,即ro数据。通过flag标识了自己是元类:
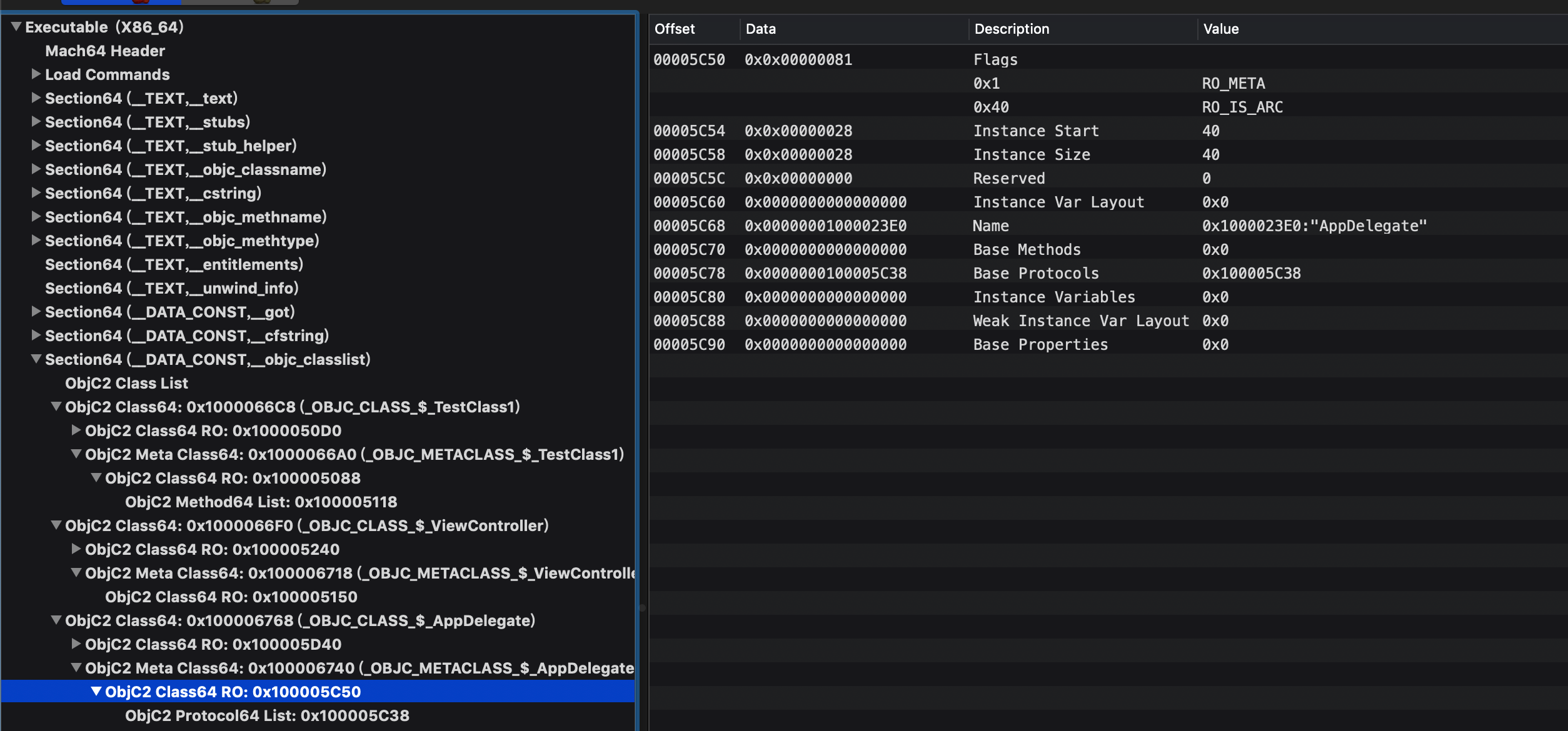
元类在面向用户的开发时是不可见的(除了runtime的部分接口暴露这个概念)。通常它只有一些类方法的指针,因为protocol中也可能存在类方法,所以protocol字段也是存在的。在编译时编译器把类方法放在元类的methodlist中,同样元类protocol的存在也让开发者可以调用协议中的类方法。
所以运行时系统中对每一个类保存了唯一的一份类数据和元类数据,所有的方法调用,协议,属性等等都只有一份。实例中只保存了isa和成员变量所需要的空间,这也是为什么instance start永远都是8,要给isa留位置啊。
那么一个实例在调用时怎么确定到指定的method的呢,便是通过isa和selector共同决定。调用程序是只需要通过isa找到对应的类或元类,然后查找方法列表即可找到对应的汇编指令了。所以调用的本质是由isa和selector,这也是为什么KVO通过isa swizzing实现方法替换。
编译时编译器会把OC的方法调用转换为msgSend,这个函数有默认两个,一个调用的对象,另一个是selector。在汇编的角度看,即入栈对象的地址,selector地址以及剩余的参数。selector是运行时系统创造的抽象概念,只给出了objc_selector这么一个不透明的东西,并没给出结构定义,不过根据runtime提供sel的内存构造可以猜测出它的结构就是这样的,是的就是仅仅只是一个字符串。。。
1 | struct objc_selector { |
那么怎么一个简单的字符串怎么实现调用呢?便是通过isa,调用时传入的第一个参数为对象地址,取第一个字节获取isa。通过isa来决定从哪里开始查询方法,类的isa指向的是元类,元类的isa指向的是父类的元类。
那么实例呢,实例的创建都是通过调用new或者alloc在运行时实现的,也就是它的isa是由运行时系统决定的,而运行时系统在创建实例是会把它的isa指向类本身,首先看下arm64架构下isa具体的结构:
1 | union isa_t |
可以发现isa不单单是指针,它是一个union结构,既可以单纯的指向class的地址,也可以附带更多的信息。之所以这么做是因为虽然64位系统,但是至少一半的地址是小于等于33位的,所以isa做了一个优化,使用第一个bit,nonpointer来标志是否开启了指针优化,当地址小于等于33位时,nonpointer置为1,元类地址保存在shiftcls。其它位保存了更多信息。当大于时,isa指向的是内存元类的地址。
所以实例调用方法时,isa可以找到类的地址,查询类中的方法列表(-开头的实例方法)。对类调用时,isa为元类查询的是元类中的方法列表(+开头的类方法)。如果当前类找不到方法,则查找父类时,实例的调用也只会在实例方法中找。而类的调用只会在类方法中查找。所以即使selector相同,实例方法和类方法也不会冲突。这样就通过元类和类把实例方法和类方法区分开了。
所以在实例方法中self为第一个参数即实例本身。而在类方法中self也为第一个参数,即类本身。
当然runtime也做了 一些cache的优化,以及查找不到时候的方法转发,就不赘述了。至于为啥OC对空对象发调用不会crash,也是runtime系统的处理,以arm64下runtime的汇编实现为例:
1 | //cmp表示检查x0和0这个立即数,x0为地址,如果为则正是0x0 |
Protocol
protocol在OC开发非常常用,它可以实现mock对象,也可以实现类似多继承的等等效果。那么protocol到底是什么呢,在OC世界几乎所有东西都是_objc_object_t的子类,显著特点就是有个isa标注自己是什么东东,protocol虽然长的奇怪,但是它也是objc_objct_t的子类,因此它也有isa,它的结构如下:
1 | struct protocol_t : objc_object { |
编译器解析到@Protocol格式的Protocol定义然后在mach-o中以上面的格式记录,注意在编译器的世界里万物皆符号,此时会创建__OBJC_Protocol_$_NSObject的符号,address指向的就是存在具体信息的地址。而解析到类时如果发现conforms某些协议,则会把这个符号对应的Protocol地址指针加入到当前类的protocols指针数组。可以发现虽然Protocol的数据里有method list,property list等,并且每一项都有具体的描述,但是却没有指向具体实现。下面是NSObject协议的method list。可以看到address都是空的:

也就是protocol只是一个描述文件,描述了类具有什么特性,但是真正的实现并不一定存在,只是绕过了编译器的静态检查。可以当做一种软继承,字面上的继承,但是实际怎么样要看类本身。因此它的编程哲学就很明确了就是面向接口,甚至根据不需要对象。
当然这只是OC中的protocol,很明显有一个缺点就是缺乏一个默认的实现,把全部的任务都交由了具体类实现。而在swift中可以通过对protocol进行扩展添加默认实现,也算是对OC的痛点的一个解决。
还有一点是编译时protocol的isa字段 都是空的,只是在runtime加载时才把protocol类本身作为它isa,因为它并不需要元类,也可以说它就是自己的元类。
由于protocol结构中的protocols数组使得它也有了继承的能力,编译器在解析protocol时会把它父协议加入到这个protocols指针数组中来提升它的能力。因此即使方法的符号在当前的protocol中找不到,还会沿着继承链查找。
那么方法到底是怎么一个东东呢?
方法
通过对类的分析可知,在class的数据中即runtime中所谓的ro有一个baseMethods字段,然而在此处只是一个指针,以下面这个类为例:
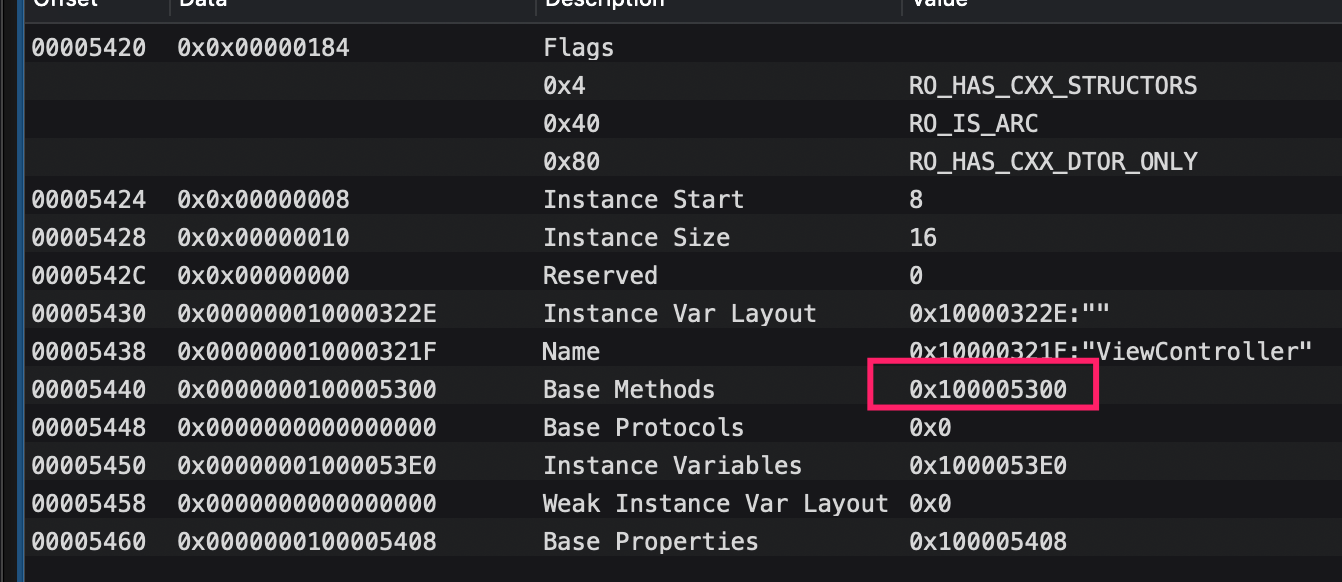
首先需要了解下method的数据结构,通过runtime源码可知大致如下:
1 | struct method_list_t { |
可以发现指向的是__objc_const段的数据(可以发现基本字符串相关信息都在TEXT段,指针之类的数据都放在DATA段)。找到指针所指的数据如下:
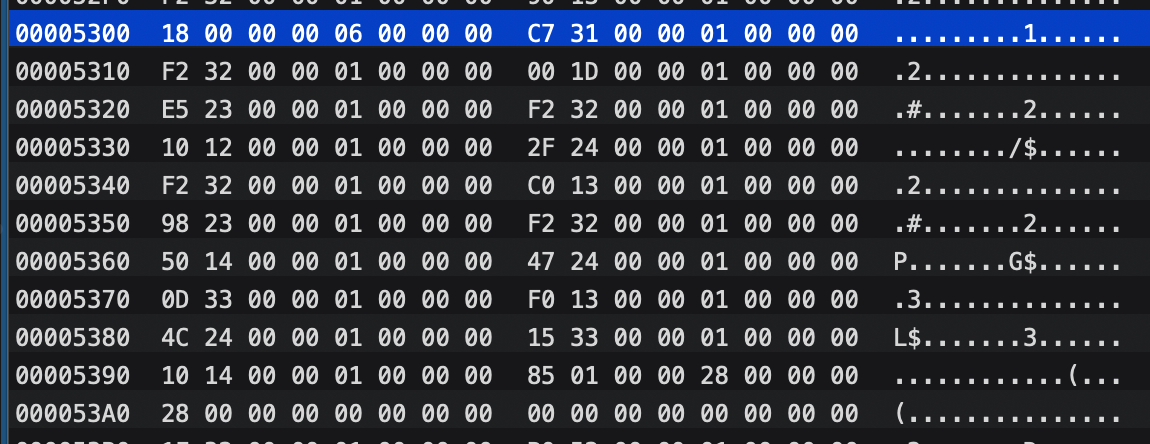
所以要解读这段代码就得按着格式来:
1.前4个字节表示为method结构占用内存大小,每一块尺寸为(0x18 & ~0x03 = 24) 。由于method_t实际就是3个指针在64位系统下占用24个字节。这里的计算规则是runtime源码来的。
2.接下来4个字节表示方法个数为0x06。这个类里共两3个实例方法,一个属性,多出来这个方法为.cxx_destruct(后面会分析它)。
3.之后3个字节表示第一个method的信息。
4.后续是剩下5个method的信息。
我们来查看一下这些Method是如何在mach-O中保存的,这里method是3个字节大小分割的,共6个,先以第一个为例,第一个字节指向``__objc_methname段来获取方法名,即SEL`:

第二个字节指向__objc_methtype段来获取方法的typeencoding,表明返回值为void,第一个参数为OC对象(NSObject*),其实就是self。第二个参数为selctor(:):

第三个字节指向方法具体实现,即__TEXT段的汇编实现:
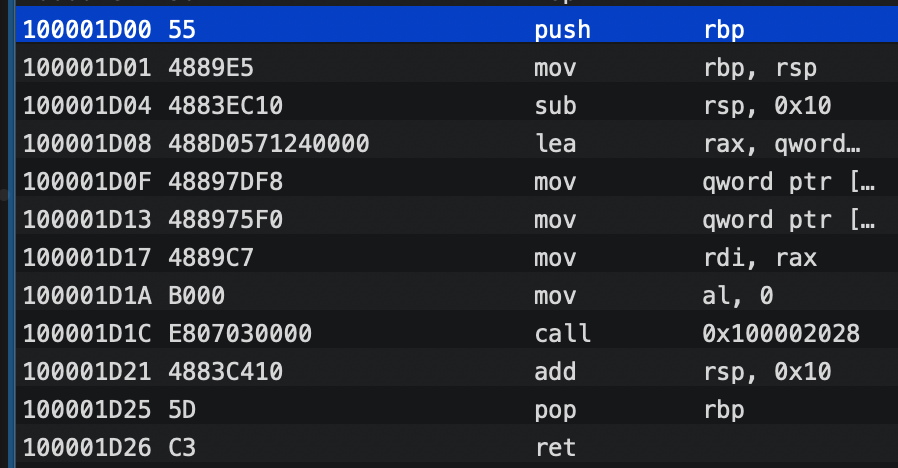
这里可以得出结论:方法最终对应的都是汇编代码,在实际运行时即转换为对应的机器指令。所以无论OC的方法还是C的函数说白了都是指向的一段机器指令,符号(仅仅指函数相关的符号)只是辅助编译器找到这一段机器指令。
至此我们已经知道了方法在mach-O中的呈现形式,那么在运行时又是怎么加载到运行时系统的呢。在运行时库加载image之后会对类进行解析,将这一段方法相关数据转换为method_list_t,之后将mach-O转换来的ro数据copy到运行时的rw中,同时把分类以及运行时添加的方法等等动态添加到rw的methods中:
1 | void attachLists(List* const * addedLists, uint32_t addedCount) { |
编译时得到仅仅是ro,在运行时我们所做的修改都在rw上,所以可以动态添加方法。可以看到rw上的methods实际为一个链表数组。并且新加入的methodlist都是放在链表最前面。因此由于分类晚于类加载,所以分类里的methodlist反而放在methods前面,如果有运行时添加方法,则放的更前。
而方法在进行动态调用时,在methods中查找时按顺序遍历所有的methodlist,因此后加入的method反而优先遍历,如果有重复的方法,则后加入先响应,因此分类中方法一定不要和原类重复,否则调用的是分类中的方法:
方法查找过程
1 | static method_t * |
由此可知:方法名相同时只会调用最后加载进来的方法(分类,运行时加载的等等)。因此可以利用分类计数覆盖原来的实现。当然如果想调用所有的实现,还可以通过runtime遍历全部方法再调用。
成员变量
OC的类本质上就是结构体的封装,每个类在实例化时只有数据段是私有的,而代码段是共享的(通过isa找到类的methods)。所以只需要几个字节存放成员变量的数据即可。在编译时即需要确认类的实例所需要空间,并且绝对不允许运行时修改,因为如果运行时可以随意修改,那么同一个类的多个实例空间不一致,在进行赋值等操作时必然可能导致严重的内存问题。当然这里不包括运行创建的类,它的ivarlayout可以在类register之前随意修改。但是一旦确定之后都是不允许再修改的了,就如同字节序一样,类的内存布局也是禁忌,随意修改可能会导致踩内存的崩溃,甚至整个代码数据错乱。
ro文件中有4个字段与实例相关:
Instance start在64位系统上永远都是8,因为要第一个字节指向的一定是ISA。
Instance Size描述了这个类实例的大小,即成员变量在经过字节对齐之后的内存和+8。
Ivar layout描述了内存布局。
instance variables指向了实例变量结构地址。
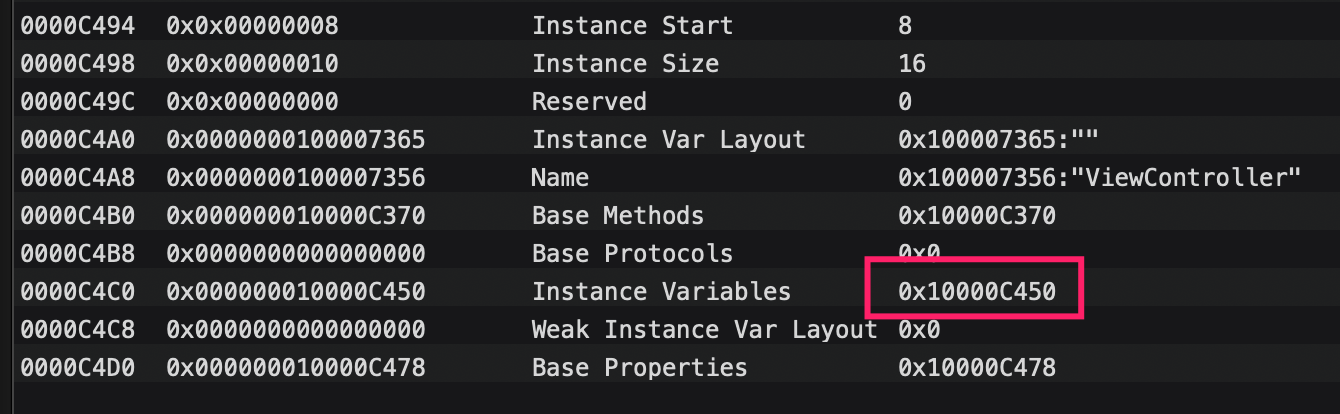
类在进行实例化是即使通过runtime中存储的类的信息进行的,根据类再编译时获取的实例大小来开辟内存空间:
1 | uint32_t unalignedInstanceSize() { |
可以发现虽然实例大小在编译时确定了,但是运行时系统根据CoreFoundation的要求,必须大于等于16字节,即没有任何成员变量的类也至少得占用16个字节,虽然通过runtime获取的的值可能为8(无任何成员变量)。
Ivars信息存在在__objc_const段,不过在不同的架构下还不一样,结构体的定义如下:
1 | struct ivar_list_t |
我们找到上图中的ivars指向的内存可以看到如下,此时我们采用的是arm64的结构进行观察:
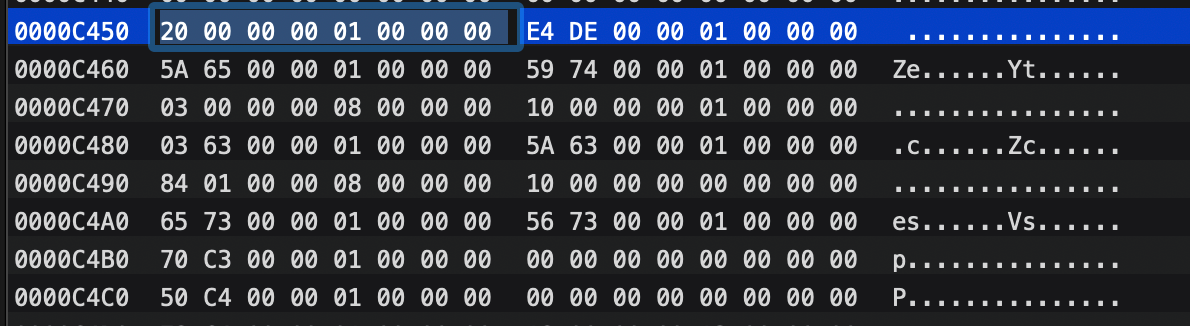
前8字节为ivar_list的数据,前4个字节描述了ivar结构体块大小为0x20即32个字节,就是64为系统下ivar_t的结构体大小。后4个字节描述了ivar数量为1。
后面跟随的则是每个ivar的信息。根据上图可知:
1.前8个字节0x10000DEE4指向的的数据为偏移。可以在__objc_ivar段找到,即0x08:

2.name为0x10000655A指向字符串。竟然也是放在__objc_methname段,可见这个段处理OC的方法名,还是存放了实例变量名,这也就是成员变量为啥是_修饰的:

3.type为0x100007459指向字符串。竟然是放在__objc_methtype段:

4.偏移为0x03,这里是的偏移实际是位,即二进制左移3位即以8字节对齐,这里再次体现了设计哲学,通过位域运算使用小数字表达大数。
5.大小为0x08,因为它就是一个NSString的指针。
那么运行时系统又是怎么添加Ivar的呢,过程代码如下:
1 | ivar_list_t *oldlist, *newlist; |
运行时系统支持都对运行时添加的类动态添加Ivar,但是一旦注册后不能再次改变,并且不能重复添加,那么是如何做到的呢:
1 | //一旦类被realized之后,运行创建类被register之后就不能添加了 |
property
property也是OC里的一个特别概念,可以理解为对成员变量的包装,通过@property声明的变量在编译时会被添加到property列表,同时产生成员变量和set get方法,编译器会自动将成员变量和property合成,例如通过_name和self.name都可以对成员变量name进行修改和访问。
由于property可以自定义属性,导致比成员变量更大的定制性,所以通常推荐在头文件中公开的成员变量采用property方式来公开。例如头文件中设置为只读。又或者在利用@dynamic来禁止自动合成,又或者采用copy来修饰字符串成员变量等等。。。
property的在Mach-O中的结构就不详细分析了,和成员变量类似的结构体数组。只需要知道property的结构如下,名字和成员变量名相同,属性设置则用于辅助编译器来限制开发者行为,或是一些别的功能。
1 | struct property_t { |
这里探究一下property和成员变量到底有什么区别:
通过访问类的成员变量值有两种方式,一种是直接_name这种修改成员变量,一种是self.name这种方式通过property生成的get方法来访问。两种到底哪种好呢,记得在我刚接触iOS开发时总是听人说用self.name这种方式无论是修改还是访问都比较好,那么事实真的是这样吗?
通过LLDB来反汇编出这两种的汇编实现,当通过_name方式访问成员变量时的汇编指令如下:
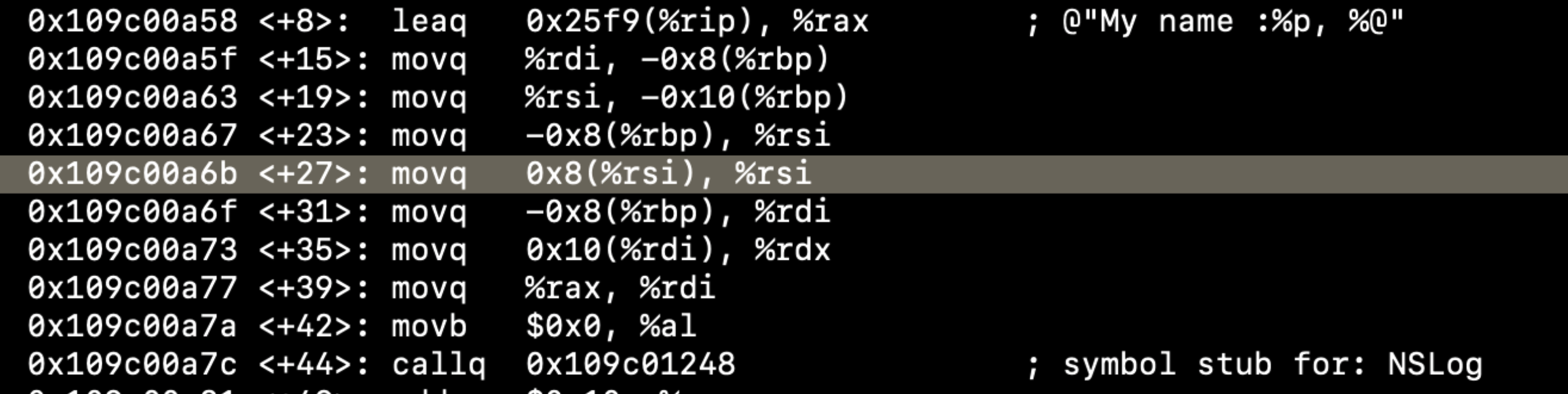
可以发现通过_name直接访问成员变量利用的是位移,只需要几行机器指令,而且具有原子性,因为_name实际上会转换为self->_name。
当通过self.name访问成员变量值的时候汇编指令如下:
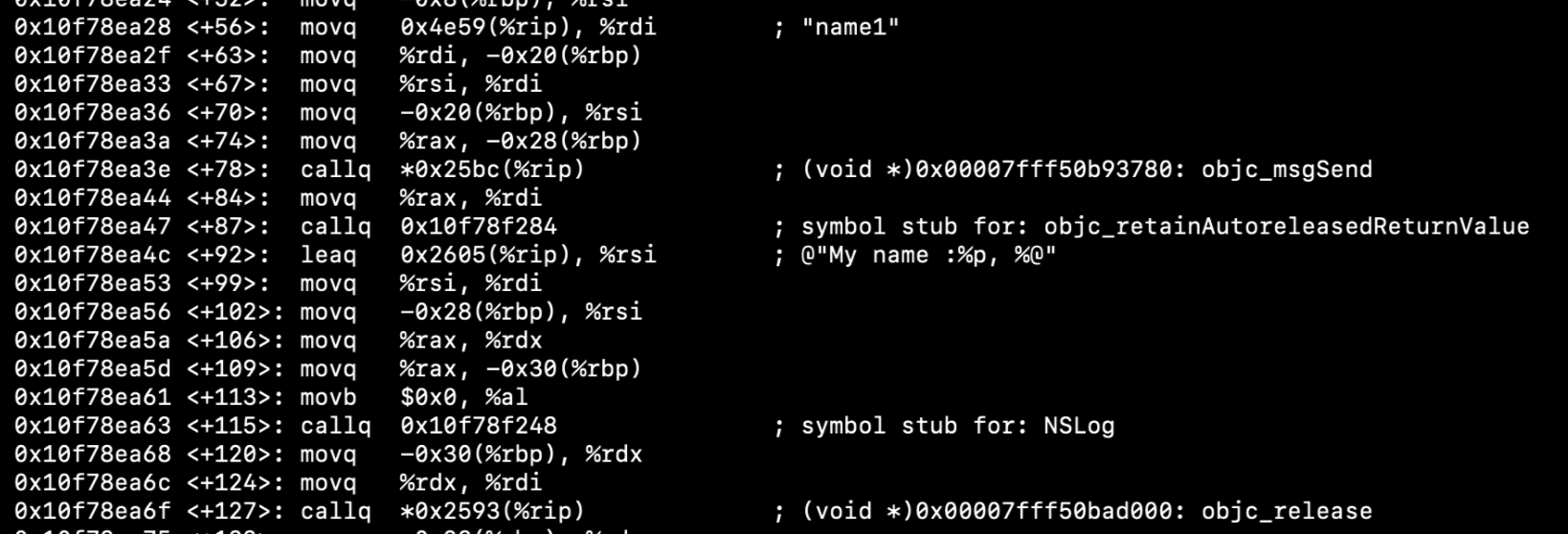
可见此时访问成员变量时走的runtime调用get方法(如果没有重写get方法则调用的是objc_getProperty方法),然后在返回了一个值,在使用完之后还需要释放掉(因为这里的属性是noatomic修饰的):
1 | id objc_getProperty(id self, SEL _cmd, ptrdiff_t offset, BOOL atomic) { |
不过本质上还是通过地址偏移来获取的成员变量值,只是走了一套runtime的流程,所以看起来反而性能损耗会更大。
但是采用和属性式访问和修改还是有很多优点的:
1.调用动态的get set方法给了开发者自定义的机会,例如懒加载这种。
2.对于KVO的值必须通过self.name =方式来触发set方法。
3.可以实现非原子性的操作,由于成员变量时直接赋值是原子性的操作,而noatomic的修饰的属性相当于单独copy了一份。
4.通过属性修饰成员变量,例如readonly,copy等等。
所以可以得出结论,如果没有特殊需求,采用直接访问成员变量的方式获取或者设置成员变量值会更快,但是存在KVO,懒加载等等时必须使用self.name形式。
引用计数与sidetable
C,C++,OC这些语言优良的性能有一部分原因得益于其垃圾回收机制,尤其是这种使用指针的语言,可以做到内存的极致优化。而引用计数技术就是他们的的垃圾回收机制核心,原理是通过一个数字来记录对象被引用的次数,一旦引用计数为0则释放内存。
它的原则是谁创建谁销毁,需要开发者来管理引用计数(arc计数除外),所以必定需要有一个东西来记录引用计数,通常得是一个map。当然这样就有一个问题就是每次都得查询,而运行时系统做了个很好的优化,把引用计数保存在了isa里面,前面分析知道isa的64个bit并没有完全占用,会保存引用计数信息在extra_rc字段。这样直接访问isa就可以知道当前对象的引用计数避免每次都取查询引用计数表。
isa里面的nonpoint描述了是否通过isa保存信息,当这里是开启的,则可以在isa中保存引用计数。extra_rc字段描述当前引用计数,因为bit位有限,因此当操作能表示的最大数值时,就无法保存了。has_sidetable_rc字段描述是否采用sidetable保存引用计数,此时has_sidetable_rc会被置为1,则再对该实例修改引用计数时就得去sidetable中查找了:
1 |
|
引用计数的查询如下:
1 | inline uintptr_t objc_object::rootRetainCount() |
前面分析过了标志是使用isa表示更多信息,所以如果没有开启,则引用计数就不可能保存在isa里面,只能通过slidetable保存了。反之引用计数优先保存在isa,如果isa保存满了,则放到slidetable里面。
sidetable是一个广泛的概念,结构如下,不仅保存了引用计数表refcnts还保存了弱引用表weak_table:
1 | struct SideTable { |
实际上运行时系统中保存的是一个8/64个SideTable长度的数组SideTables()中:
1 | alignas(StripedMap<SideTable>) static uint8_t |
可见SideTables就是由StripeMap这个模板创建出来的包含SideTable数组的结构题,内存占用在iPhone上就是一个8个元素的sidetable数组。其他为64,可以理解有这么多张表来存放引用计数和弱引用。
StripeMap重载了运算符[],这里既是如何通过实例对象查找到对应slidetable的原理:
1 | T& operator[] (const void *p) { |
所以在runtime里可以看到SideTables()[self]这种方式来找到sidetable,所有的对象都根据地址影视到SideTable数组中的某一个,即某一个表中。
至于为什么要这么做,1.是为了防止单个SideTable过大维护不方便,查找不易。2是由于每一次操作或者查询引用计数都需要对表进行上锁,如果全部在一个表锁住,会非常影响性能。
引用计数的记录也是通过位运算来实现的,并且有几个特殊的为用于表示信息:
1 | // The order of these bits is important. |
此时再回过头看一下查询引用技术表的实现:
1 | size_t objc_object::sidetable_getExtraRC_nolock() |
自此引用计数技术是如何在运行时系统是使用的已经基本弄懂了。通常引用计数技术伴随的是对象内存的自动析构,那么对象内存的析构是怎么实现的呢?
dealloc与.cxx_destruct
dealloc方法是一个与alloc方法相对应的NSObject基类方法,在对象实例被释放前由运行时系统自动触发以供在此时做一些操作,比如移除观察者等等。
当引用计数变为0时运行时系统自动调用该方法。此时的对象isa的的deallocating字段会被标记为1。表示对象将要被释放了,如果此时
1 | ...省略... |
运行时系统会进行保护,如果对一个已经处于deallocating的对象进行释放会触发crash,结果如下:
1 | //如果已经处于deallocting, |
这也是在开发中比较常见的一种crash,通常发生于多线程情况下对单例的属性进行修改时,因为运行时系统中的赋值不是一个原子性操作,还伴随着retain和release。 因此可能导致导致retain和release次数没有匹配上,如果碰见这种错误就要考虑对通过加锁等方式
同样在dealloc方法中不要在对self做过多操作了,避免触发release引起该崩溃。
对代码分析可知dealloc实际是一个内存释放的前置操作,真正根源上的内存释放则是通过基类的dealloc实现,在arc下回自动依次调用父类的dealloc方法,这是析构的特性决定的,因此最终会自动调用NSObject的dealloc方法,在此时才进行真正的数据析构过程,分好几步:
1 | id object_dispose(id obj) |
object_cxxDestruct做的事情如下的具体实现如下,它会依次从子类到父类调用其cxx_destruct方法:
1 | static void object_cxxDestructFromClass(id obj, Class cls) |
但是至此我们仍然未知cxx_destruct到底做了什么,前面知道编译时该方法已经被编进了mach-O。所以可以查看相应的汇编实现,我们找到代码中类TestClass1的cxx_destruct的汇编实现如下(因为对x86_64更熟悉点就以x86_64的为例),这个类共有3个成员变量,第一个为int型,后两个为NSString型:
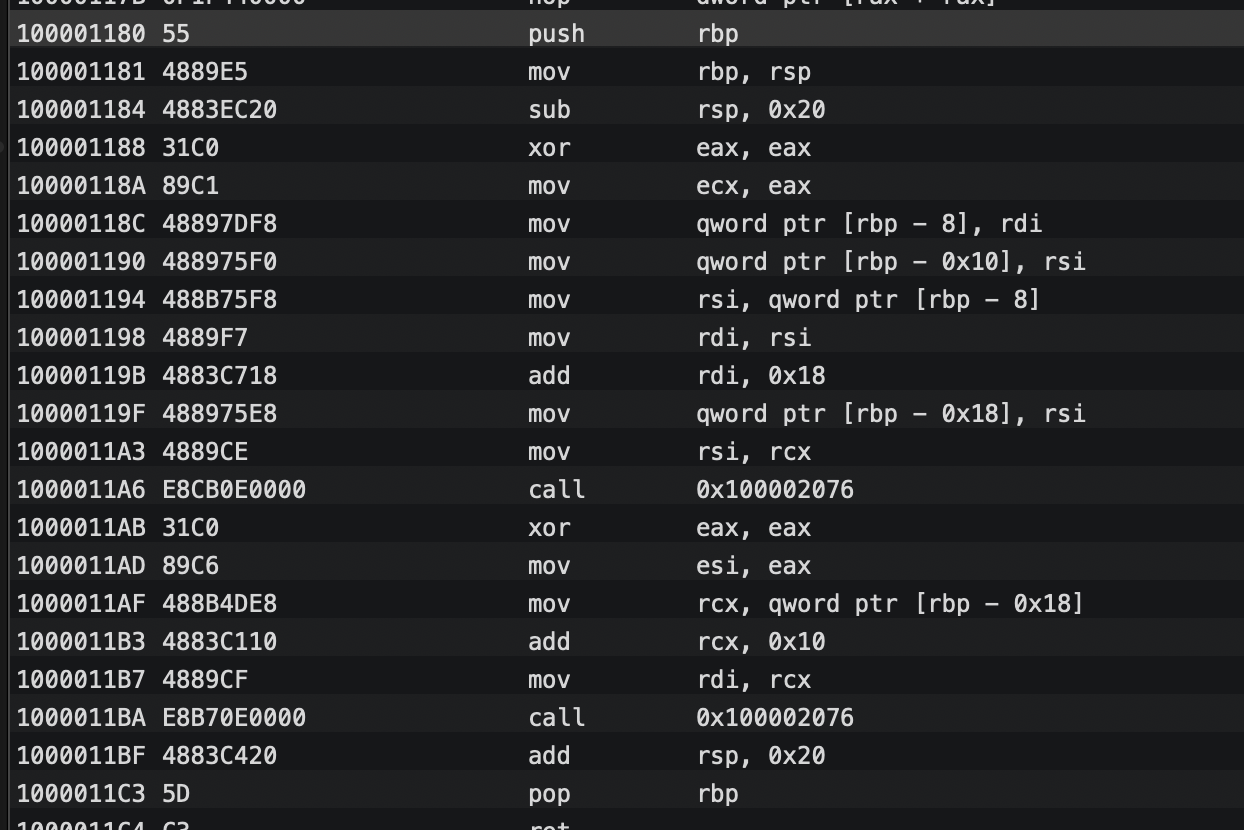
以我这点浅薄的汇编能力按行分析一下。。。
1.栈顶和栈基址寄存器处理。实例大小只有16个字节。利用异或重置寄存器等等。
2.分别取了把rdi寄存器和rsi寄存器的值,方法栈基址寄存器向前偏移0x08和0x10的指针赋值给在寄存器rdi和rsi。应该就是成员变量name的地址和obj的地址。
3.找到偏移为0x18这个成员变量的内存地址存放到rsi寄存器中。
4.然后竟然call了0x100002076查找一下竟然是_objc_storestrong的stub(此时我又检查了一遍arm64下的mach-O,竟然也是这样的。。。。)
5.重复对另一个最后一个成员变量,偏移为0x10这个做同样的操作。
5.重置栈顶寄存器,出栈。
这里分析下为啥这里会调用_onjc_storeStong:
1.当前内存需要释放没毛病,但是成员变量也是OC对象,因此也需要走一遍release的流程。所以这里通过_objc_storestrong来实现其释放。
2.通过对另一个类观察可以发现只有两个NSStirng的成员变量才会参与cxx_destruct的析构,所以这里只是利用了这个方法依次对OC变量的成员进行析构。
3.由于对成员变量调用了release,如果没有其它对象引用它则它也会被释放,这样就实现了OC对象的成员变量的依次释放。
所以析构的过程如下:
graph LR A[OC实例] --> B[最后一个OC类型成员变量] B --> c[倒数第二个OC类型成员变量] c --> d[...]
后来发现大佬sunnyxxx也写了一篇文章,从LLVM源码来分析的,也就进一步证实了这段汇编代码的产生的原因:https://blog.sunnyxx.com/2014/04/02/objc_dig_arc_dealloc/。
总结可知
1.只有含有OC类型成员变量的类才会在编译时注入cxx_destruct方法。
2.实例添加过多的OC类型成员变量会大大增加析构的流程。
3.可见OC对象的OC类型成员变量的析构是按高地址到低地址来的(从ivars列表反向顺序)。
动态链接信息
LC_DYLD_INFO也是LINK EDIT段的一部分,提取出来是方便dyld快速找到,而且位于符号表,字符表等信息之前。dyld通过它进行进行rebase,首先看一下结构:
1 | struct dyld_info_command { |
苹果为了数据安全提供了ASLR,所谓地址空间随机化即虽然每个image加载时虚拟地址是一整块,但是ASLR技术就使得起始地址并不唯一,每次都是随机的,这样即使知道mach-o的结构也不能根据起始地址+偏移来修改函数。所以我们再取mach-o中数据时都需要通过dyld获取slide`,再结合虚拟地址获取:
1 | _dyld_get_image_vmaddr_slide(i) |
Rebase Info
所以每次dyld加载image都需要先rebase,dyld中是通过寻找一块能容纳下所有segment的内存之后,
1 | uintptr_t lowAddr = (unsigned long)(-1); |
之后根据这逐个对segment进行地址偏移映射:
1 | //获取原来的文件偏移 |
这样就解决了ASLR技术导致的内存偏移问题。而rebase info中则保留了segment是如何偏移的:

每一个rebase info都是一个字节的数即0x00-0xFF,分别表示操作数和数据,通过和mask按位与获取信息,高4位表示操作字,低4非表示立即数,具体的枚举可以参考<mach-o/loader.h>:
1 |
这里分以一个0x11为例。 所以操作为REBASE_OPCODE_SET_TYPE_IMM,type为REBASE_TYPE_POINTER。而第二个0x22表示操作数为REBASE_OPCODE_SET_SEGMENT_AND_OFFSET_ULEB,值为2,即表示对segment 2偏移,紧跟着是偏移值为数值。一般DO_REBASE命令时才会根据前面一段的重定位信息进行rebase`。
而codesign则是另一个安全策略,用于验证app是没有被恶意篡改过的,简单说就是根据开发者的证书加密源代码数据的哈希,这样第一保证了确定是没有第三方动过App,第二保证了再审核过后开发者也不能动App。codesign是位于mach-o最后一段数据,但是其实它并不是对全部数据一次性的哈希然后加密,而是针对每个数据页进行的。
Bind info
而绑定信息则描述的是在通过dyld绑定之后的符号的信息,此时会根据这里找到源符号指针,然后把地址赋给源指针,这样动态绑定只需要绑定一次即可:

例如这里是_objc_msgSend在动态绑定完后BIND_OPCODE_SET_SEGMENT_AND_OFFSET_ULEB和offset共同标识了要写回的位置,即第二个segment的0偏移处,即_got的d一个函数指针,恰好就是_objc_msgSend的函数指针,所以这时候前面看到的Non-Lazy symbol ptr就不再是空指针了,而是指向了对象的内存,下一次访问该符号时便可直接把指针指向的数据插入。
Lazy bind info和bind info基本上是一样的就不在详述了。
Export Info
根据官方描述,它是一个树状结构,terminal size描述节点的大小,chindren count描述子节点的个数,flag描述节点的属性。next node描述下一个节点。大致可以简略如下:
graph TD A[_] --> B[_mh_execure_header] A --> C[main] A --> D[OBJC_] D --> E[CLASS_$_] E --> F[TestClass] E --> G[ViewController] E --> H[AppDelegate] E --> I[SceneDelegate] F --> J[1] F --> K[2]
每个结点都通过next node指向下一个节点,每个节点都有child count描述有几个分支,Node Label描述节点的字符串。Terminal size描述节点最终大小,当且仅当叶子节点的值才大于0,此时flag存放了节点属性,symbol offset存放符号对应数据的偏移,例如TestClass1根据偏移找到数据为objc_data里的类信息。例如mian根据偏移找到的就是函数在TEXT段的汇编代码。
这样所有的符号字符就成了一个字典树,提高字符查找效率。之前一直好奇怎么通过符号找到指针,原来这样即可以通过这个来进行快速的查找。
探究的意义
1.我们观察一下classlist和classrefs,两者都是指针数组区别在于前者保存了所有存在的类,而后者则只保存了被引用的类(是符号被引用而不只是import),所以可以通过差集来判断哪些类存在但是未被使用,但是实践可以发现有一个坑点是仅仅通过NSClassFromString等runtime的方式使用的类也不会出现在这里,因为mach-o显示的只是编译后的信息,只是检查了代码中有没有对这些类符号进行使用。而runtime这些高级的东西,在编译时认为就是一坨字符串而已。
2.理解了动态加载的过程可以知道,移除不需要的库文件可以提高加载的速度。过度使用分类也会影响加载速度。
3.理解了符号在mach-o中如何找到函数指针的,我们就可以动态的改变C函数的实现,处理Fishkook这样的应用场景,甚至可以进行一些热更新的效果。
4.发现方法名成员变量名等等会存在于mach-O,是否应该考虑把类作为namespace,优化方法名和变量名长度来减少mach-O大小。
5.理解了成员变量和属性的区别可以帮助我们写出更高性能的代码。
6.理解了内存布局可以知道,对象时如何在内存中存在的,方法的调用原理,可以让我们写出更高效的代码。
7.以后写代码时注意抽象,和利用技巧压缩代码量也可以有效的减少mach-O的大小。
参考资料
https://github.com/facebook/fishhook
http://opensource.apple.com/tarballs/dyld