前言
今天被一位北美的同事的comment了一个memcpy使用的代码,大致如下,在解析数据时把数据段的2个字节的数据长度memcpy到NSInteger *上:
1 | - (void)updateData:(NSInteger *)dataLength data:(uint8_t *)data { |
这位同事的comment如下:

大意是这样使用memcpy不安全并且性能不好,应该采用他建议的方式,那么这里到底有什么门道呢?
memcpy
memcpy是string.h中的声明的一个Libc库函数,作用是把第二个参数的内存,按第三个参数的长度拷贝到第一个参数。
1 | void *memcpy(void *__dst, const void *__src, size_t __n); |
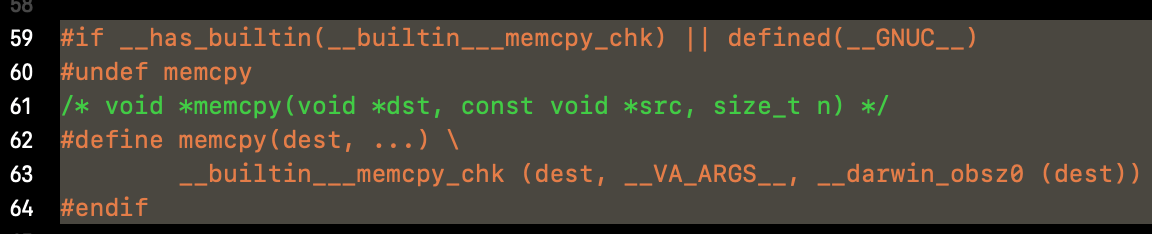
在drawin系统中,则是采用了一个编译器内置函数__builtin___memcpy_chk来替换掉了memcpy:
首先可以学习一点的是这种用宏命令文本替换非常实用,举个例子,假如不希望工程的NSLog或者printf打印信息除了符号替换还可以通过宏命令替换的方式干掉:
1 |
|
总之可以知道是把memcpy替换成了内置的__builtin___memcpy_chk,那么这个编译器内置函数是干什么呢?
gcc和clang等等编译器都有一些builtin函数,类似宏命令,会在编译时把原来的函数替换掉,以到达优化。宏命令通常是文本替换,而内置函数通常是指令级别的替换,能够做很多优化以及避免函数调用的开销等等。
clang所有的内置函数可以在Builtins.def中找到。首先下载clang源码,先看看Builtins.def中的声明,这里只关注__memcpy_chk:
1 | BUILTIN(__builtin___memcpy_chk, "v*v*vC*zz", "nF") |
Builtins.def中声明了所有的内置函数,这个BUILTIN宏的第一个参数是一个枚举值,会对应到一个函数名,第二个参数为函数的返回值与参数类型,第三个参数为函数的描述,nF表示这是一个Libc/libm的函数,并且没有throw。更多信息感兴趣的话可以细看一下。
打开bstring.h,可以看到对memcpy更多的描述。而且非常巧clang正好就拿memcpy来作为内置函数的例子:
1 |
|
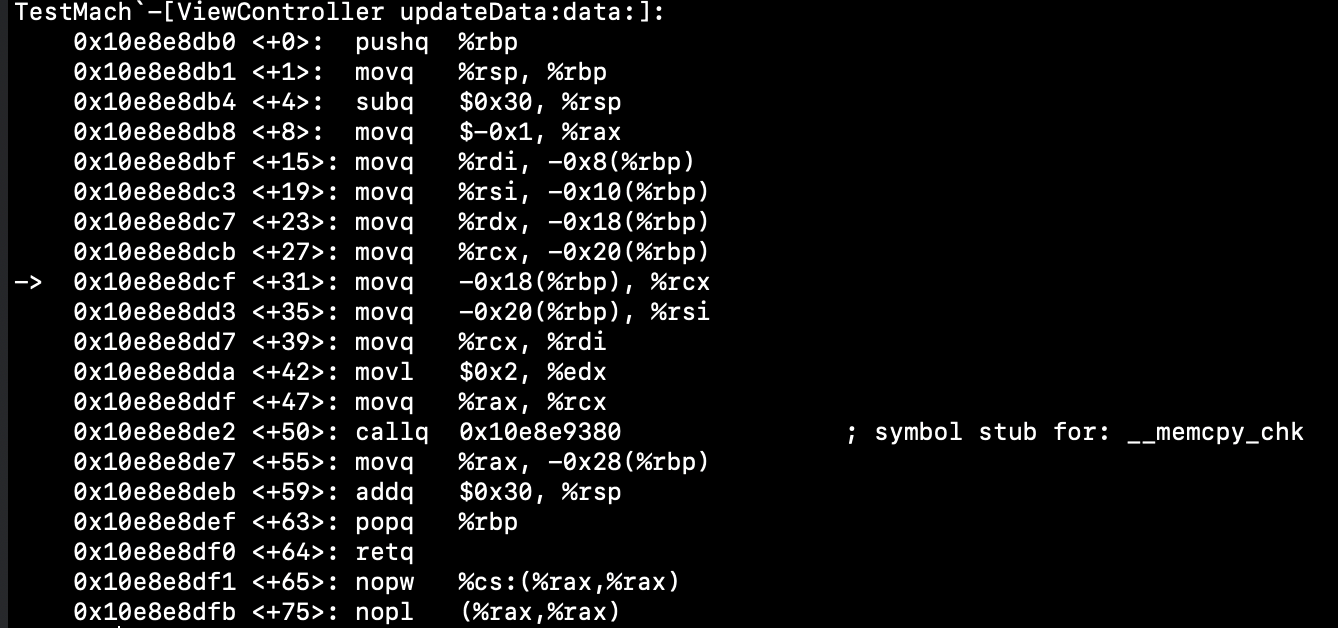
通过反汇编可以看到确实在运行时call的是__memcpy_chk这个函数(此时编译器优化并没有开启):
那么为啥要替换成__memcpy_chk呢?
因为memcpy实际是一个很不安全的函数,可能导致踩内存和overlap等问题,因此LLVM(GCC)采用了内置函数__memcpy_chk来包装这个方法,会在编译时进行一些检查,编译器前端会在IDE上通过警告的方式提示用户使用有误,在bstring.h这个例子中可以看到很多使用它的情况,并且会产生的各种各样警告信息。所以内置函数除了提高性能,也可能是是做一些安全保护。
两种实现的区别
先思考一个问题,程序在运行时CPU是如何知道变量长度的,怎么知道如何取值的?
这个问题其实很傻。。因为CPU是不需要知道变量长度的。对于程序控制器来讲,他就是一个没有感情的无限循环机器。。。根据汇编指令一条条取指令然后执行,然后取下一条指令然后再执行。对于8字节的变量取值时可能就是一个movq,对于1字节的变量可能就是一个movb,2个字节的话就是一个movw。它只是按着指令一条一条执行。
所谓变量长度只是编译器的魔法,编译器在解析上层语言时会根据变量的类型转换成各种各样的指令,例如按照同事说的写法:
1 | *dataLength = (NSInteger)*(uint16_t *)data; |
编译器会转换成什么样呢(Debug无优化下):
1 | ... |
首先可以看到一点,原来的call(甚至第一次可能还需要动态绑定)都没了,完全变成了数据的转移和拷贝,那么faster是必然的。
并且由于uint16_t *显式类型转换的原因,这里确保只拷贝2个字节,并且由于dataLength的类型修饰为NSInteger所以拷贝到4个字节中(可以理解就是取出两个字节放到一个4个字节的整数中)。所以数据肯定是没问题的。这里的精华就在于这个uint16_t *。
假如去掉显式的uint16_t *会怎么样,可以看到去掉后实现变成了下面这样:
1 | 0x10836dde4 <+20>: movq -0x20(%rbp), %rcx |
但是我memcpy也是只拷贝了2个字节啊?为啥我就不安全呢?
那是因为字节序,同事提出这种方式相当于把2个字节的数值转换成4个字节的数值,无论大小端,会自己适配好内存布局。
但是memcpy只是从起始字节开始拷贝,假如数据长度为0x10,dataLength初始化为0x00000000,则在小端模式下memcpy之后:
1 | *dataLength内存为: 10 00 00 00 |
可见是没有毛病的。但是如果是在大端模式下呢:
1 | *dataLength内存为:10 00 00 00 |
显然数据就有问题了。
所以他说这里不安全,由于arm和x86都是小端模式,所以这个数字在进行memcpy时会这样并不会出问题,假设是跨平台层的,就可能会导致问题。
编译器做的优化
我们都知道LLVM的优化是很牛逼的,前面都是在没开编译器优化的情况下时进行的反汇编,如果把编译器优化设置为-Os呢:
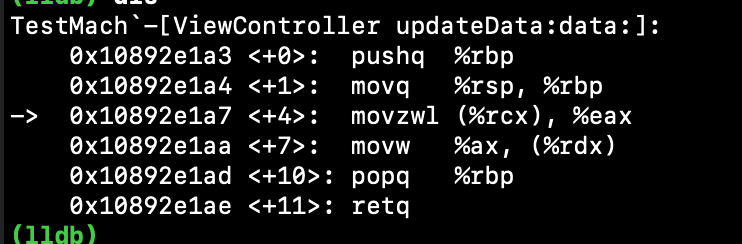
牛逼。。。直接把memcpy干没了,直接操作寄存器转移2个字节过去就了事了。。。
那么是不是意味着同事说的代码没啥意义呢?
不,默认debug下是不开编译器优化的,更重要的编程习惯与思考。而且至少在打release包时可以编的更快快一点。。。
而且知道了计算机是如何取内存的,还可以有更多的应用场景,例如当我想计算具有float变量的类的hash时,float变量是无法进行移位的,那么就可以通过取内存的原理,把4个字节的数值都取出来然后转成一个int型变量,就可以做位移操作了。当然啦你也可以采用memcpy。
1 | float floatValue = 1.0001; |